Gpt 4o로 유튜브 영상 자막 엉어로 번역하기
Goraniworks / June 2024 (1052 Words, 6 Minutes)
GPT-4로 유튜브 영상 번역하기
오늘은 내가 AI로 유튜브의 영상 자막 번역하는 법을 알려줄께. GPT-4를 이용해서 SRT 자막 파일을 한국어에서 영어로 번역하는 거야. 파이썬 스크립트로 openai api를 통해 번역할 거야. 최대 입력 토큰에 한계가 있기 때문에 주어진 SRT 파일을 여러 구간으로 나누고, 각 구간을 번역한 다음, 최종 결과물을 새로운 SRT 파일로 저장할 거야.
자막은 개인 소장용으로 만들었고, 원본영상의 저작권자와는 어떠한 협의도 없었음을 밝힌다.
동영상 다운, whisper로 음성인식
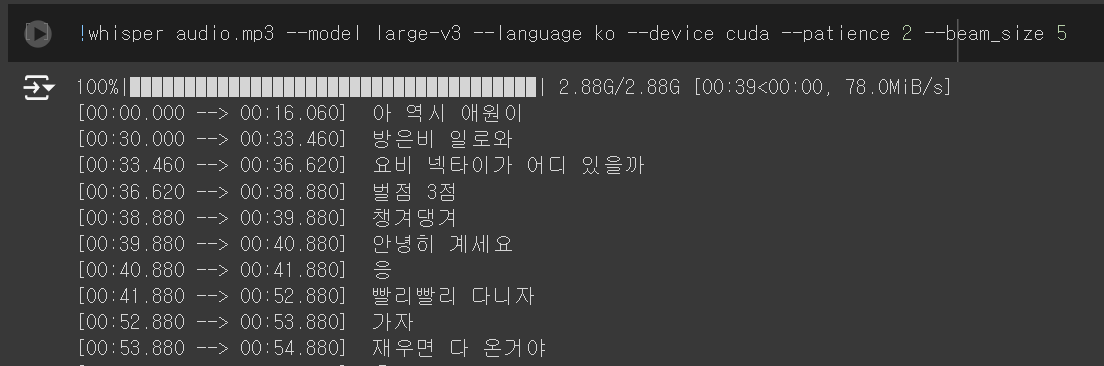 일단 번역하기 위해 한국어 자막이 필요해. 동영상의 음성 파일을 다운로드 해. (여기서는 다운로드 하는 방법을 알려주지 않을거야. 구글 약관 위반이거든.)
whisper이용방법은 내가 예전에 했던 프로젝트 참고해 줘.
일단 번역하기 위해 한국어 자막이 필요해. 동영상의 음성 파일을 다운로드 해. (여기서는 다운로드 하는 방법을 알려주지 않을거야. 구글 약관 위반이거든.)
whisper이용방법은 내가 예전에 했던 프로젝트 참고해 줘.
gorani works - Whisper 음성인식 대작전
필요한 패키지와 API 설정
먼저, 필요한 패키지를 가져오고 OpenAI API 키를 설정해야 해. 하기전에 OpenAI API 에 충분한 deposit이 있는지 확인해봐. 유료 서비스 이거든. 챗gpt와 api는 결제를 따로 하는거야. 걱정하지마 이 프로젝트의 총비용은 1$정도야. 처음 가압하는 친구들은 결제를 하지 않고, 계정 생성해서 나오는 기본 용량으로 충분히 할 수 있어.
import openai
import os
# OpenAI API 키 설정
openai.api_key = 'YOUR_API_KEY_HERE'
SRT 파일 나누기
이 함수는 SRT 파일을 지정된 범위로 나눠줘.
def split_srt(file_path, ranges):
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
parts = []
for start, end in ranges:
part = []
in_range = False
for line in lines:
if line.strip().isdigit():
current_index = int(line.strip())
if start <= current_index <= end:
in_range = True
else:
in_range = False
if in_range:
part.append(line)
parts.append(part)
return parts
텍스트 번역하기
이 함수는 GPT-4를 이용해서 주어진 텍스트를 번역해줘.
def translate_text(text):
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "Translate the following Korean text to English."},
{"role": "user", "content": text}
]
)
return response.choices[0].message['content'].strip()
SRT 구간 번역하기
이 함수는 나눈 SRT 구간을 번역해줘.
def translate_srt_parts(srt_parts):
translated_parts = []
for part in srt_parts:
korean_text = ''.join(part)
english_text = translate_text(korean_text)
translated_parts.append(english_text.split('\n'))
return translated_parts
번역된 SRT 파일 저장하기
이 함수는 번역된 SRT 구간을 새로운 파일로 저장해줘.
def save_translated_srt(translated_parts, output_file):
with open(output_file, 'w', encoding='utf-8') as file:
for part in translated_parts:
for line in part:
file.write(line + '\n')
전체 코드 실행
다음은 전체 코드를 실행하는 부분이야. 범위를 설정하고, SRT 파일을 나누고, 각 부분을 번역한 다음, 최종 결과를 저장해.
# Define the ranges
ranges = [(0, 55), (56, 106), (107, 165), (166, 229), (230, 257), (258, 283), (284, 322), (323, 384), (385, 442)]
# Split the SRT file into parts
srt_parts = split_srt('viviz.srt', ranges)
# Translate each part using GPT-4
translated_parts = translate_srt_parts(srt_parts)
# Save the translated parts to a new SRT file
save_translated_srt(translated_parts, 'viviz_eng.srt')
print("Translation completed. The translated file is saved as 'viviz_eng.srt'.")
이렇게 하면 주어진 SRT 파일을 여러 구간으로 나누고, 각 구간을 GPT-4를 이용해 번역한 다음, 최종 결과를 새로운 SRT 파일로 저장할 수 있어. API 키를 설정하고, 범위를 잘 맞춰서 사용하면 돼. 잘 해봐!
프로젝트 후기
- 놀랄만큼 저렴한 비용
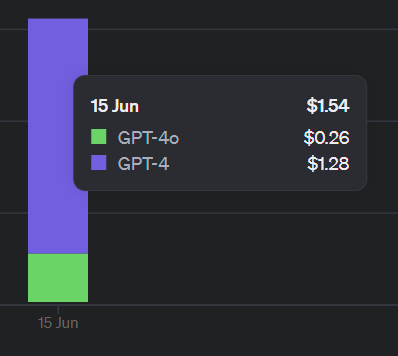 자막 길이가 440 문장정도 되는 데, 비용은 놀랄 만큰 저렴했다. 같은 파일을 두 번 실행해 보았다. gpt4는 1.28$이고, gpt4o는 0.26$이다. 최신모델인 gpt4o에 토큰 알고리즘이 개선되었다는 소식은 들었지만 이정도로 효율적일줄은 몰랐다.
자막 길이가 440 문장정도 되는 데, 비용은 놀랄 만큰 저렴했다. 같은 파일을 두 번 실행해 보았다. gpt4는 1.28$이고, gpt4o는 0.26$이다. 최신모델인 gpt4o에 토큰 알고리즘이 개선되었다는 소식은 들었지만 이정도로 효율적일줄은 몰랐다.
- 범위 정하는데 실패
gpt4o는 최대 입력 토큰에 제한이 있다. gpt4에 물어보니 50~70 문장 정도가 적당하다고 했다. 자막 내용을 분석해서 의미가 자연스럽게 구분되는 구간을 임의로 나눠서 다음과 같이 나눴는데 첫번째 문장이 짤린다. 뭐가 문제일까?
# Define the ranges
ranges = [(0, 55), (56, 106), (107, 165), (166, 229), (230, 257), (258, 283), (284, 322), (323, 384), (385, 442)]
- 컨텐츠 번역은 난이도가 의외로 높다
일반적으로 내가 AI로 번역작업을 해보면 난이도가 다음과 같다.
다큐멘터리, 뉴스 < 개인 라이브방송 < 예능방송 < 라디오
다큐멘터리나 뉴스같이 공적인 내용을 다루고 화자 1명인 컨텐츠는 사람의 손이 필요하지 않다. 지금 독일이나, 영국의 언론 유튜브 채널가서 유튜브의 내장 자동번역기능을 켜 보아라. 완벽하다. 문제가 되는 것이 ai는 배경지식이 없고, 화면을 보지 못해 영상의 내용을 인식하지 못하고 화자를 구분할 수 없기 때문에 한 명 이상의 화자가 나오고, 문화적인 뉘앙스가 가득한 이야기, 인칭과 시점을 다양하게 오가는 대화에서는 반드시 잘못된 번역이 나게 되어있다. 사람도 마찬가지 이다. 화면을 보지 않고 문화적인 배경지식이 없고, 대사의 화자를 표기하지 않는 스크립트를 받았을때 사람도 번역이 어려울 것이다.
문화적인 배경지식
대사의 화자를 표기
이 두가지가 현재의 번역의 어려움이다. 반대로 이것의 비용을 싸게 해결할 수 있다면 K컨텐츠 자동번역도 꿈은 아닐거라 생각한다. 해외의 노동력을 이용한다면 좋지 않을까?
- 여전히 검수하는데 드는 시간이 길다
코드를 gpt4에 요청해서 작성하고 파일을 번역하는데 드는 시간은 얼마 걸리지 않았다.
실제로 api를 이용해 번역하는데 드는 시간과 비용은 다음과 같다.
gpt4 약 9분 11초 비용 1.28$
gpt4o 약 2분 51초 비용 0.29$
하지만 다음 시간도 고려해야 한다.
한글자막을 whisper로 생성한 한국어 자막 결과물을 검수하는 시간 : 3시간
gpt4o가 번역한 영어 자막 결과물을 검수하는 시간 : 4시간
기타 분석하고 처리하는 시간 : 2시간
나는 영어를 잘하는 편도 아니고, 읽는 속도도 느리다. 이상한 부분을 찾아내려면 차분히 모든 문장을 사람이 읽어야 하는 데 여기서 시간이 너무 오래 걸린다. 컴퓨터로 처리하는 시간까지 합해서 총 9시간 정도가 걸렸는데 14분짜리 영상을 번역하는데 이정도의 시간이 걸린다면 내 기준에서는 실패한 프로젝트이다.