Whisper 음성인식 대작전
Goraniworks / April 2024 (1310 Words, 8 Minutes)
AI 서비스 알아보기 1 - Whisper
openAI 는 챗 GPT만 있는것이 아니다. 매달 새로운 연구 결과가 쏟아지고 있으며 현재 제공하는 수십개의 서비스가 있다. 요즘 AI라고 해서 말이 많지만 실제로 관심을 가지고 사용해보는 사람은 극히 적다. 이 글을 읽고 한번 실행해 본다면 당신은 인류의 상위 5%안에 드는 사람이 되는 거다.
Whisper는 openAI에서 September 21, 2022 에 출시한 자동 음성 인식 서비스이다. (automatic speech recognition - ASR) 음성파일을 여기에 넣고 실행하면 꽤 높은 정확도(95% !!!)로 텍스트화를 시켜준다.
다음은 Whisper홈페이지에 나온 소개글이다.
Whisper는 웹에서 수집된 680,000시간의 다국어 및 멀티태스킹 지도 데이터로 훈련된 자동 음성 인식(ASR) 시스템입니다. 우리는 이러한 크고 다양한 데이터 세트를 사용하면 악센트, 배경 소음 및 기술 언어에 대한 견고성이 향상된다는 것을 보여줍니다. 또한 여러 언어로 전사할 수 있을 뿐만 아니라 해당 언어에서 영어로 번역할 수 있습니다. 우리는 유용한 애플리케이션을 구축하고 강력한 음성 처리에 대한 추가 연구를 위한 기초 역할을 하는 모델과 추론 코드를 오픈 소스화하고 있습니다.
깃허브에서 파일을 다운받아 직접 실행 해 볼 수 있게 되어있다. 8년된 고물 컴퓨터로 30분짜리 음성파일을 작업하면 8시간이 걸린다. 이걸 돌릴 만큼 사양이 되는 컴퓨터는 굉장히 비싸다. 하지만 구글 코랩을 이용한다면 이 고민은 필요없다.
구글 코랩이란… GPT에 물어봤다.
구글 코랩(Colab)은 구글에서 제공하는 클라우드 기반의 무료 Jupyter 노트북 플랫폼입니다. 이를 통해 사용자는 브라우저에서 직접 파이썬 코드를 작성하고 실행할 수 있으며, 구글 드라이브와 쉽게 연동되어 협업과 파일 관리가 용이합니다. 또한, 구글 코랩은 딥러닝 실험을 위한 무료 GPU 및 TPU 사용을 지원하여 고성능 컴퓨팅 작업을 가능하게 합니다.
무료로 고가의 엄청난 GPU를 쓸 수 있는것이다.
한번 해보자
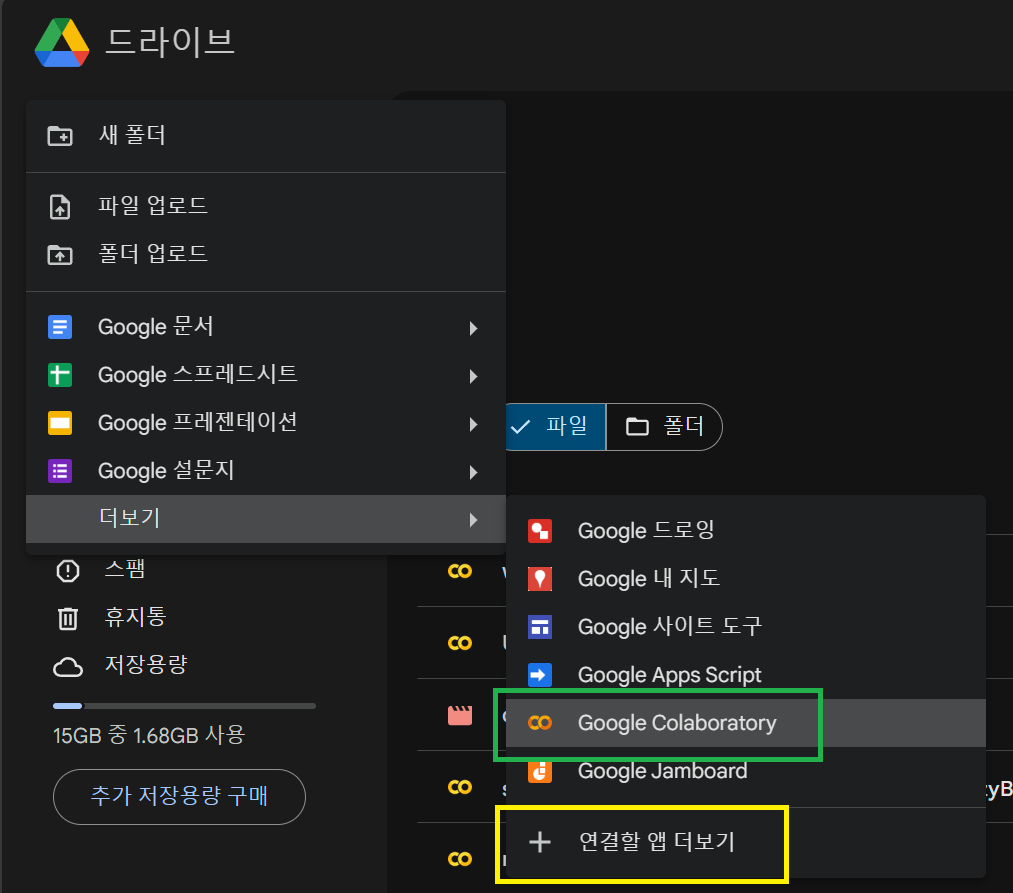
일단 구글 클라우드로 들어가 위 화면의 경로로 들어간다. 초록색 네모의 코랩이 안보이면 설치가 안된 것이니 아래 노란 네모를 클릭하여 아래 그림과 같이 코랩을 찾아 인스톨한다. 클라우드 상으로 연결해 주는 절차이니 별도 설치/다운/조작은 없다.
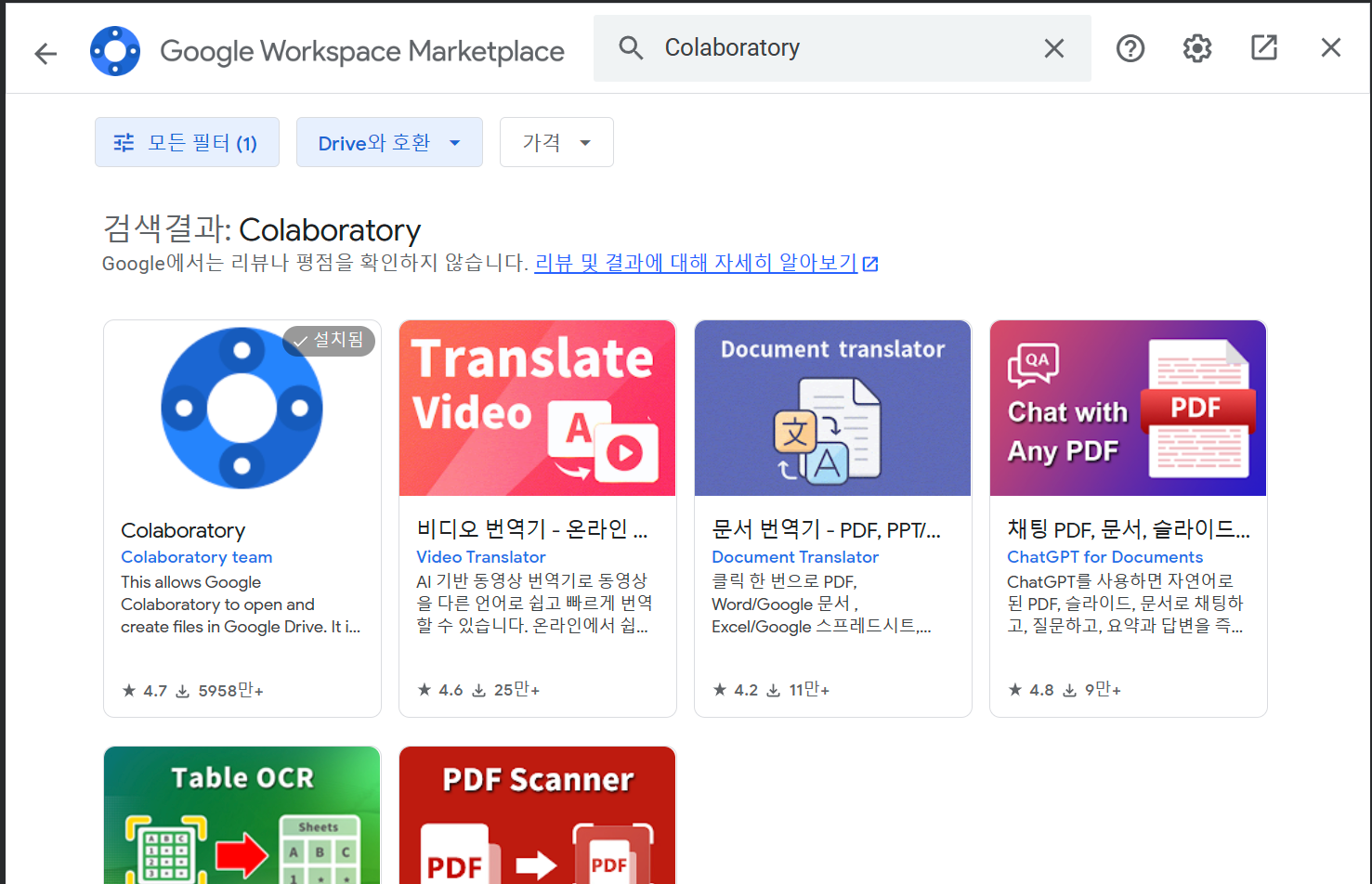
코랩에 들어 가면 다음과 같은 화면이 있다.
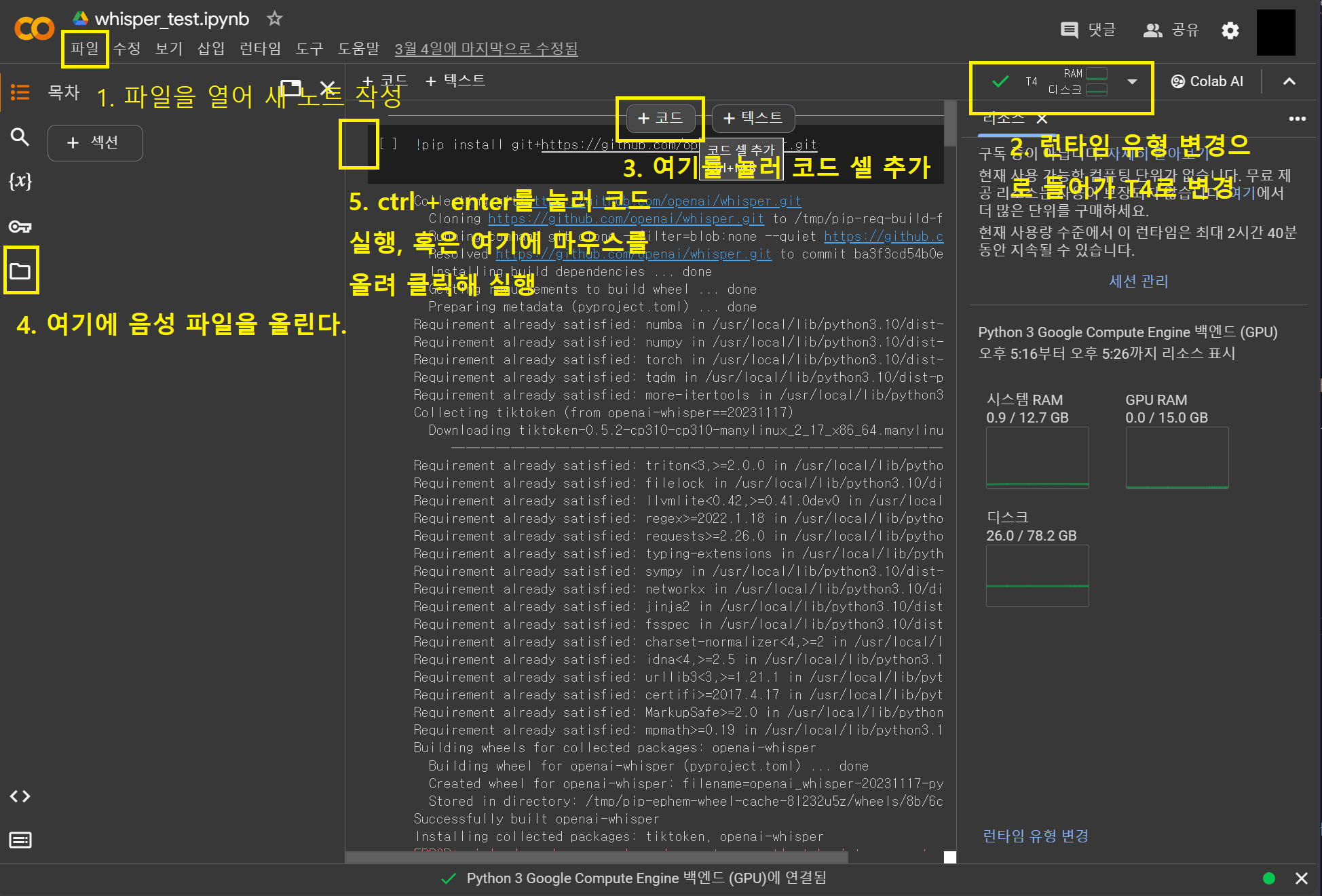
코랩에 들어 가면 다음과 같은 화면이 있다. 하나씩 따라하며 해보자.
1.새 노트 작성을 눌러 구글 드라이브에 파일을 추가한다. 우리가 작업한 파일은 구글 드라이브에 저장된다.
2.런타임 유형을 눌러 T4 GPU를 선택해 준다.
3.코드셀을 추가하고 아래와 같이 수행한다.
코드 셀을 추가하고 다음 명령어를 입력한다. 아래 명령은 openai-whisper와 관련된 파이썬 라이브러리를 가져와서 설치하는 것이다. AI 관련 라이브러리는 버전별 호환이 전혀 안되므로 주의해야 한다. 아래 조합을 찾기위해 본인은 일주일을 연구했다.
하나씩 넣어도 좋고 한꺼번에 실행해도 된다. 위에서 차례로 한 명령씩 수행된다. CLI를 쓸때는 아래와 같이 명령어 앞에 !를 붙이면 된다. 그냥 일반적인 리눅스 쓴다고 보면된다. 파이썬 코드 작성시는 !를 안붙이고 그냥 쓰면 자동인식이 된다. 코랩은 파이썬에 최적화 되어있다.
!pip install -U openai-whisper
!pip install openai
!pip3 uninstall torch torchvision torchaudio -y
!pip3 cache purge
!pip install torch==2.1.0
!pip install torchvision==0.16.0
!pip install torchaudio==2.1.0
4.폴더를 클릭해 저기에 분석할 음성 파일을 드래그해서 올린다. 음악, 동영상, 녹음파일 mp3, mp4, wav등등 동영상 플레이어로 실행할 수 있는건 다 된다. whisper 내부에 동영상 처리 플러그인이 있는 것으로 보인다. 단, 파일이 크면 분석에 시간이 오래 걸리므로 음성 파일만 올리도록 하자. 코랩에 올린 파일은 시간이 지나면 자동으로 지워지므로 작업한 파일은 반드시 내 PC나 클라우드에 따로 복사를 해놔야 한다.
5.ctrl + enter를 눌러 실행한다.
6.이 과정이 완료되면 내 코랩 노트북에 openai-whisper 가 설치된 것이다. 이것도 역시 시한부이무로 빨리 하고 싶은 작업을 해야 한다. 구글은 12시간 정도 지나면 여기 내용을 다 삭제해 버린다. 다음 문구를 입력해 실행한다.
!whisper 분석하고_싶은_음성파일.mp3 --model large-v3 --language ko --device cuda --patience 2 --beam_size 5
각 옵션에 대해 알아보자
–model large-v3 whisper에는 다음과 같이 Parameter 사이즈 별로 모델이 나눠져 있다. 상위 모델로 갈 수록 정확해지고 속도가 느려진다.
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en |
tiny |
~1 GB | ~32x |
| base | 74 M | base.en |
base |
~1 GB | ~16x |
| small | 244 M | small.en |
small |
~2 GB | ~6x |
| medium | 769 M | medium.en |
medium |
~5 GB | ~2x |
| large | 1550 M | N/A | large |
~10 GB | 1x |
–language ko 어떤 언어 모델로 선택할 거냐 하는 건데 상관없다. whisper는 어떤 언어이든지 자동으로 감지해서 인식한다. en으로 하든, ko로 하든 경험상 차이는 없었다.
–device cuda cuda코어 gpu를 이용해서 작업을 진행 한다는 것이다. 필수적으로 들어가야하는 부분이다.
–patience 2 –beam_size 5 이건 openai whisper 깃허브 디스커션에서 보고 알아낸건데, 정확도가 높아진다. 여기에 대해 어떠한 문서도 발견하지 못하였다. 저걸 디스커션에 올린 사람은 어떻게 알아냈지??
이 내용을 챗gpt에 물어봤다.
명령줄에서 --patience와 --beam_size는 특정 프로그램이나 명령을 실행할 때 사용자가 설정할 수 있는 옵션입니다. 이들은 각각 다음과 같은 의미를 가집니다:
--patience:- 이 옵션은 일반적으로 기계 학습과 같은 반복적인 알고리즘에서 사용됩니다. 특정 조건이 충족되지 않을 때까지 알고리즘의 실행을 얼마나 오래 기다릴 것인지를 결정합니다. 예를 들어,
--patience 2는 성능이 개선되지 않는 경우 2회의 반복 이후에 조기에 종료할 것임을 의미합니다. - 오디오 처리나 음성 인식과 같은 작업에서는, 알고리즘의 성능 평가나 검증 중 성능 향상이 일정 시간 동안 관찰되지 않을 때 더 이상의 학습이나 처리를 중단하도록 설정할 수 있습니다.
- 이 옵션은 일반적으로 기계 학습과 같은 반복적인 알고리즘에서 사용됩니다. 특정 조건이 충족되지 않을 때까지 알고리즘의 실행을 얼마나 오래 기다릴 것인지를 결정합니다. 예를 들어,
--beam_size:--beam_size는 주로 음성 인식이나 자연어 처리에서 사용되는 “빔 서치(beam search)” 알고리즘의 매개변수입니다. 빔 서치는 특정 순간에 탐색할 수 있는 후보의 최대 개수를 정합니다.--beam_size 5는 한 번에 고려할 수 있는 최대 후보 수를 5개로 제한한다는 것을 의미하며, 이는 보통 결과의 정확도와 처리 속도 사이의 균형을 맞추는데 사용됩니다.- 더 큰
beam_size값은 결과의 정확도를 높일 수 있지만, 계산 비용도 증가시킵니다. 반면에 작은 값은 더 빠른 처리 속도를 제공하지만, 최적의 결과를 놓칠 가능성이 높아집니다.
따라서 --patience 2와 --beam_size 5 옵션은 각각 알고리즘의 실행 중 조기 종료 조건과 탐색 범위를 제어하는 데 사용됩니다.
어쨌든 결과는 다음과 같다.
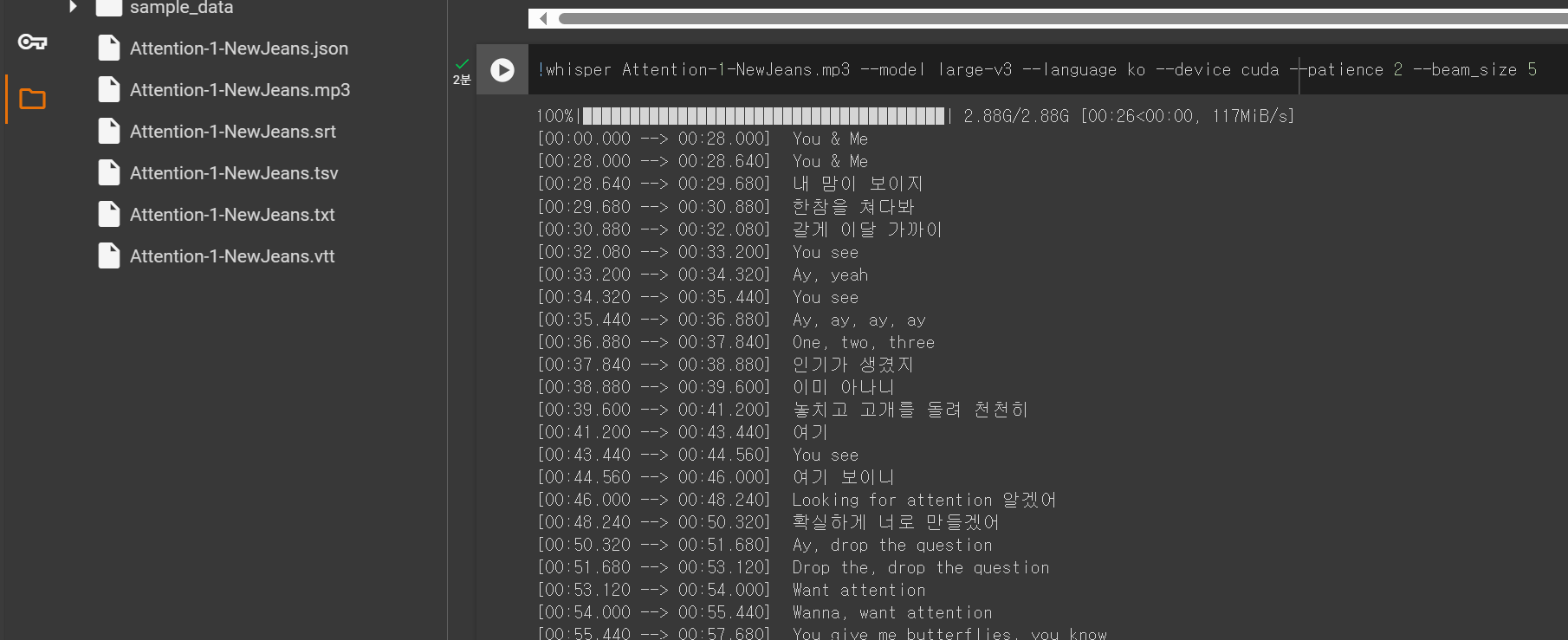
결과 검토
이 부분이 제일 중요하다. whisper는 놀라운 능력을 보여주지만 완벽하지 않다. whisper 깃허브 페이지에서 나온 정확도는 다음 표와 같다.
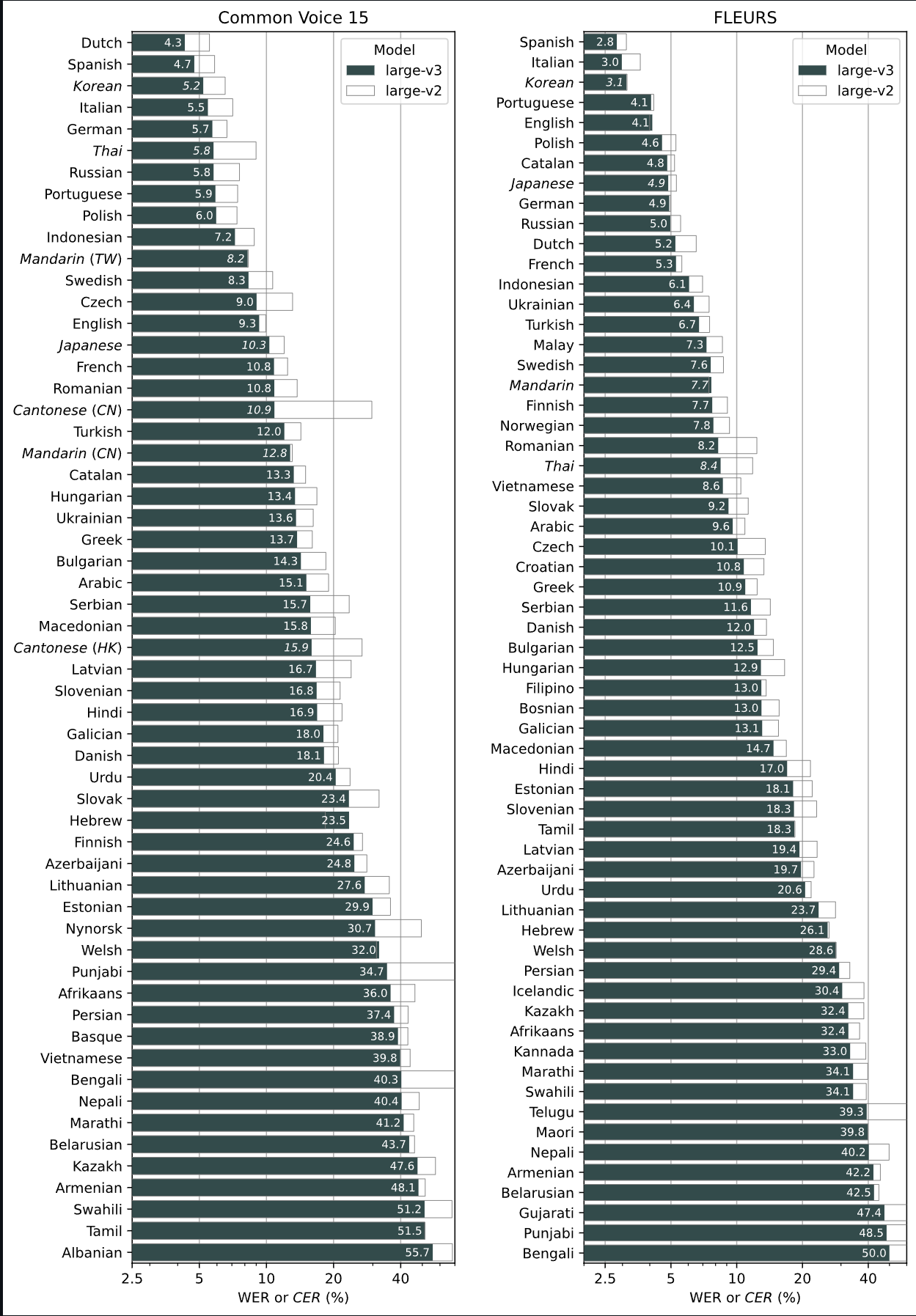
Whisper의 성능은 언어에 따라 크게 다릅니다. 아래 그림은 Common Voice 15와 Fleurs 데이터셋을 사용하여 평가된 WER(단어 오류율) 또는 이탤릭체로 표시된 CER(문자 오류율)을 사용하여 large-v3 및 large-v2 모델의 언어별 성능 분석을 보여줍니다. 다른 모델 및 데이터셋에 해당하는 추가적인 WER/CER 지표는 논문의 부록 D.1, D.2, D.4에서 확인할 수 있으며, 번역에 대한 BLEU(Bilingual Evaluation Understudy) 점수는 부록 D.3에서 확인할 수 있습니다. - whisper 깃허브 페이지
위 표에서 보면 large v3모델의 경우 5%의 오류율을 보여주는데 사용해 보면 딱 그정도다. 하지만 이 5%는 사람이 듣거나 보기에 크게 거슬린다. 만약에 10000문장이 있다고 하면 처음부터 끝까지 다 읽어야 하고, 500문장을 찾아서 직접 고쳐야 한다는 것이다. 이는 엄청난 노동력을 요구한다.
다음 결과를 보자. 뉴진스의 attention 이라는 곡이다. 음악이 나오고 발음이 불분명한 부분이 있음에도 불구하고 꽤 훌륭하게 문장을 작성하였다. //표시로 작성한 부분은 공식 가사와 틀린부분이다. 하지만 노래를 직접 들어보면 whisper가 틀렸다고 할 수 없는 애매한 부분이 거의 대부분이다.
You & Me
You & Me // #문장 두번 반복
내 맘이 보이지
한참을 쳐다봐
갈게 이달 가까이 //가까이 다가가
You see
Ay, yeah
You see
Ay, ay, ay, ay
One, two, three
인기가 생겼지 // 용기가 생겼지
이미 아나니 // 이미 아는 니 눈치
놓치고 고개를 돌려 천천히 // 고개를 돌려 천천히,
여기
You see
여기 보이니
Looking for attention 알겠어 // 너야겠어
확실하게 너로 만들겠어 // 확실하게 나로 만들겠어
Ay, drop the question
Drop the, drop the question
Want attention
Wanna, want attention
You give me butterflies, you know
내 맘은 언덕 패러독스 // 내 맘은 온통 paradise
이 꿈에서 깨워주지 마
You got me looking for attention
You got me looking for attention
가끔은 정말 헷갈리지만 분명히 // 가끔은 정말 헷갈리지만 분명한 건
You got me looking for attention
날 우연히 마주친 척할래
못 본 척 지나갈래
You're so fine
Gotta, gotta get to know ya
나와나와 걸어가줘
지금 돌아서 면은 // 지금 돌아서면
잊어, 잊어, 잊어 // I need ya, need ya, need ya
Don't look at me back // To look at me back
Hey, 다 지켰어 나 // Hey 다 들켰었나
날 보면 하트가 튀어나와 // 널 보면 하트가 튀어나와
사탕을 찾는 baby // 난 사탕을 찾는 baby
내 맘은 설레이지
Ay, drop the question
Drop the, drop the question
Want attention
Wanna, want attention
You give me butterflies, you know
내 맘은 온통 패러독스 // 내 맘은 온통 paradise
이 꿈에서 깨워주지 마
You got me looking for attention
You got me looking for attention
가끔은 정말 헷갈리지만 분명히 // 분명한 건
You got me looking for attention
You got me looking for attention
You got me looking for attention
가끔은 정말 헷갈리지만 분명히 // 분명한 건
You got me looking for attention
ATTENTION is what I want
ATTENTION is what I want
ATTENTION is what I want
ATTENTION
You got me looking for attention
더 자세한 내용은
whsper 깃허브 페이지에 가보길 권장한다. https://github.com/openai/whisper